計畫成員 : 廖弘源、王建堯
從2022年開始,廖博士的研究團隊執行由國科會資助的第二個四年期AI專案計劃 (2022/1~2025/12),每年的研究經費大約500萬左右。上一期的四年期AI專案計畫(2018/1~2021/2)廖博士的研究團隊按照科技部(現國科會)「業界出題、學界解題」的要求,與竹科上市公司義隆電子公司,雙方針對「智慧城市交通車流解決方案」進行四年的合作。為了解決義隆電子公司希望研發團隊能在edge端(i.e.十字路口)即時計算交通參數,以及在連續路口間互相傳遞交通參數,進而達到動態控制交通號誌的目的。廖博士的研發團隊隨後在2019年及2020年分別研發出舉世聞名的CSPNet及YOLOv4。從2020年至今(2023/2),全世界各行各業,包括醫療體系、天文、生物、智慧交通、智慧製造等等領域,都採用CSPNet及YOLOv4的核心技術去執行它們各自領域的物件偵測工作。截至2023/2為止,CSPNet及YOLOv4的相關論文累計被引用次數已突破11,000次。為了持續保持世界領先地位為台灣爭光,王建堯博士、Alexey Bochkovskiy、及廖弘源博士於2022年7月發佈了進階版物件偵測系統- YOLOv7。
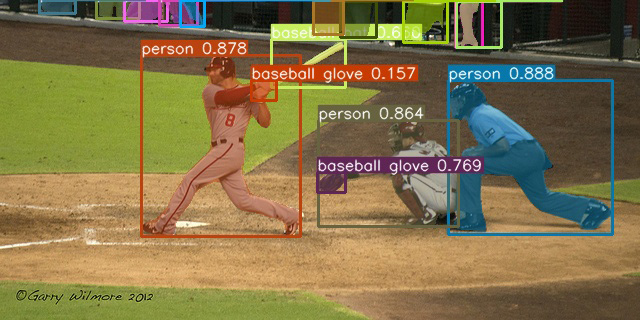
廖博士領軍的第二期AI計畫主軸是基於YOLOR之多任務電腦視覺技術之研發。YOLOR是You Only Learn One Representation的簡稱。它主要的目的是建立一個Unified Network,讓它能同時處理多重任務。隨著單一任務的電腦視覺模型無論在準確度以及速度上皆逐漸達到人類水平以上,多任務模型在近來成為一個熱門的研究議題。研究團隊在2021年於表徵學習研究所提出的YOLOR架構展現了強大的多任務泛化能力,因此研究團隊基於YOLOR開發即時多任務學習技術。但是,將電腦視覺模型落地使用,需要兼顧準確度以及速度,因此(1)有效提取多任務共有資訊與(2) 建立即時推論神經網路架構,乃是第二期AI計畫所需要克服的議題。針對第一個議題:基於YOLOR的隱式知識建模方法,廖博士團隊已於2021年初開始著墨,並成功的開發了當前最先進的即時物件偵測、實例分割、與姿態估計方法。舉例來說:YOLOR在即時物件偵測任務上,在同等的準確度下,推論速度比當前最先進方法足足快了88%;而搭載自監督學習的YOLOR更是展現了強大的表徵學習能力,比當前最先進方法提升了315%的推論速度,大幅推進物件偵測實際應用場景的廣度,YOLOR的物件偵測結果展示於圖一。

圖二則展示了使用YOLOR開發的實例分割模型預測結果。與當代最卓越的即時實例分割方法相比,YOLOR以更快的推論速度,顯著提升了整整26%的準確度(34.6%->43.6% AP),達到了一個即時實例分割方法的新高度。
在姿態估計方面,更是因為YOLOR的引進,直接降低了當前最先進方法109%的參數量(87.0M->41.6M),減少45%的運算量(145.6G->100.6G),並增進1%的AP。有關姿態估計的結果,則展示於圖三。廖博士的團隊也同時在其他電腦視覺任務如影像分割、影像描述、深度估計、與物件追蹤皆證實了基於YOLOR的多任務學習方法的優越性。針對第二個議題,廖博士團隊於2022年7月提出了ELAN類神經網路架構,與YOLOR結合並同時解決了物件偵測領域中的幾個新議題,並設計了當代最先進的即時物件偵測方法 - YOLOv7。在結合YOLOR與YOLOv7後,上述的多種電腦視覺任務表現都獲得了顯著的提升。
