PIs: Mark Liao and Chien-Yao Wang
Starting in 2022, Dr. Liao's research team started executing the second four-year AI project funded by the National Science Council (2022/1 ~ 2025/12), approximately $170,000 in annual research funding. In the last four-year AI project (2018/1 ~ 2021/12), Dr. Liao's research team followed the requirements of the Ministry of Science and Technology, i.e., "Let industry raise real-world issues, and let academia solve them", and conducted a research project with Elan Electronics, a listed company in Hsinchu Science Park, on "Smart City Traffic Flow Solutions" case. To solve ELAN's expectation that the research team can calculate traffic parameters in real time at the edge (i.e., crossroads), so as to achieve the purpose of dynamically controlling traffic signs, Dr. Liao's research team respectively in 2019 and 2020 developed the world-famous CSPNet and YOLOv4. From 2020 to now, various industries around the world, including medical systems, astronomy, biology, smart transportation, smart manufacturing and other fields, have adopted CSPNet and YOLOv4 technologies to perform object detection in their respective fields. As of June 2023, the cumulative number of citations of CSPNet and YOLOv4 related publications has exceeded 14,000. To continue to maintain the world's leading position and win glory for Taiwan, Dr. Liao's research team released an advanced version of the object detection system-YOLOv7 in July 2022.
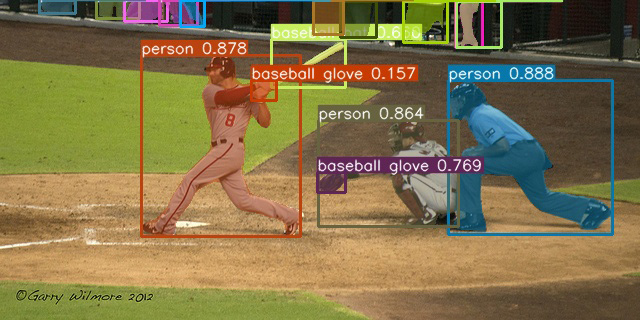
The main goal of the second 4-year AI project led by Dr. Liao is the research of multi-tasking, computer vision technology based on YOLOR. YOLOR is the abbreviation of You Only Learn One Representation. Its main purpose is to build a unified network and enable it to handle multiple tasks at the same time. As single-task computer vision models gradually reach human-level performance in both accuracy and speed, multi-task models have become a hot research topic in recent years. The YOLOR network architecture proposed by the research team in the direction of representation learning has demonstrated strong multi-task generalization capabilities, so the research team developed real time multi-task learning technology based on YOLOR. However, the implementation of computer vision models needs to take into account both accuracy and speed. We will discuss in two directions. First, we need to extract common information for multi-task efficiently; and second, build a neural network architecture for real-time inference. For the first topic, YOLOR-based implicit knowledge modeling, Dr. Liao’ s team has started to work on it in early 2021, and successfully developed the most advanced real-time object detection, instance segmentation, and pose estimation methods. For example, YOLOR is 88% faster than the current state-of-the-art method in the real-time object detection task under the same accuracy requirements; and YOLOR equipped with self-supervised learning has shown amazing representation learning ability, 315% faster inference speed than the state-of-the-art method. This result greatly promotes the breath of practical application scenarios for object detection, and the results of object detection based on YOLOR are shown in Figure 1.

In Figure 2 we show the prediction results of the instance segmentation model developed with YOLOR. Compared with the most outstanding real-time instance segmentation method, YOLOR significantly improves to the accuracy by 26% (34.6%→ PIs: Mark Liao and Chien-Yao Wang 43.6%) AP with a faster inference speed, reaching a new height of real-time instance segmentation methods.
In terms of pose estimation, the introduction of YOLOR directly reduces the amount of parameters of the current state-of-the-art method by 109% (87M→ 41.6M), reduces the amount of computation by 45% (145.6G→100.6G), and increases the AP by 1%. Regarding the result of pose estimation, we show it in Figure 3. Dr. Liao’ s team also demonstrated the superiority of YOLOR-based multi-task learning method in other computer vision tasks, such as image segmentation, image description, depth estimation, and object tracking. For the second issue, Dr. Liao’ s team proposed the ELAN-based neural network architecture in July 2022, combined with YOLOR and solved several new issues in the field of object detection at the same time. We have therefore designed the most advanced real-time object detection method-YOLOv7, and the performance of various computer vision tasks mentioned above has been significantly improved.
