計畫成員 : 劉庭祿、陳煥宗
本多年期計畫「發展電腦視覺核心技術與其自動化應用」從2021/11開始執行,研究內容著重於開發電腦視覺核心技術與建構深度學習模型,並致力推廣相關技術於智慧製造的實際場域應用。在本計畫前期之四年(2018~2011) AI計畫中,我們的研究著重於 (1)自然語言驅動的電腦視覺技術研發,包含開發基於自然語言的語示影像分割(Referring Image Segmentation)技術、提出語示3D示例分割(Referring 3D Instance Segmentation)技術。(2)零例(zero-shot)物件分類技術,包括開發利用mixup與meta learning機制,來生成 virtual classes 與samples,進而提升零例物件分類模型效能;並提出Query-driven Multiple Instance Learning (qMIL)架構,可用於解決零例物件分類問題。(3)單例(one-shot)物件偵測技術,包括開發利用co-attention與co-excitation的單例物件偵測技術、開發基於Adaptive Image Transformer模型的單例物件偵測技術等。本計畫除了延續前期相關研究成果外,並專注於開發更具挑戰性與實用性的電腦視覺技術在智慧製造的自動化應用,其主要規劃聚焦於下列五項研究議題。
- 開發基於影像與視訊的異常偵測技術:為了建構適用於智慧製造的電腦視覺核心模組,本計畫探討異常檢測的兩個應用情境。第一種應用情境是基於影像的物件瑕疵偵測,其目的是發現目標物件中的異常缺陷。我們所提出的Metaformer模型,可從影像中判定與分割出物體的異常瑕疵,若該物件類別在模型訓練時為unseen,可藉由少數該類物件影像對Metaformer元調優,即可進行異常偵測。第二種情境是基於視訊的異常事件偵測。具體來說,本項應用是從給定的視訊中偵測分割出有異常事件發生之影像片段。關於視訊中異常事件偵測研究,根據訓練資料的標註有無,其對應問題又可分為one-class與weakly-supervised,我們提出了可同時適用於這兩類問題的自監督稀疏表示方法(參見圖 1),來有效解決視訊中異常事件之偵測與辨識。
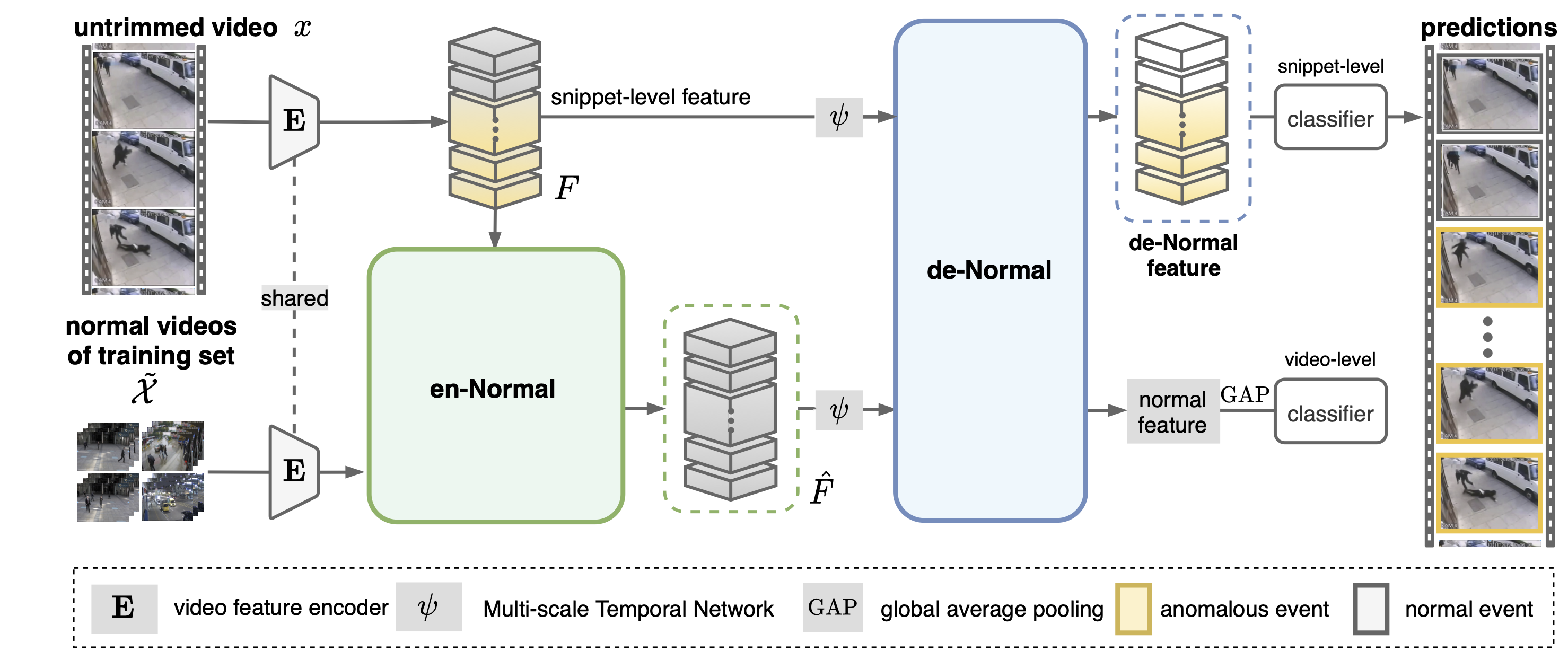
圖一:基於自監督稀疏表示(S3R)的視訊異常事件偵測架構 - 開發高挑戰情境下的物件辨識與偵測技術:影像視覺分類的日常實際應用常涉及複雜的資料分佈,例如細緻分佈和長尾分佈。本研究旨在開發可一併解決這兩項具有挑戰性問題的方法。我們經由所提出新的正則化技術,建構對抗性損失函數來加強模型學習訓練。在每個訓練批次中,我們從自適應批次預測(Adaptive Batch Prediction, ABP)矩陣導出其相對應的自適應批次混淆範數(Adaptive Batch Confusion Norm, ABC-Norm, 參見圖 2)。ABP 矩陣由兩部分所組成,包括一個自適應模組,用於對不平衡分佈進行分類編碼,另一個模組用於批量評估softmax預測。ABC-範數產生基於範數的正則化損失,從理論上可以證明它是與秩最小化密切相關的目標函數之上限。在此議題上,我們的現階段研究重點為如何將ABC-Norm實現於增量學習的泛化上。
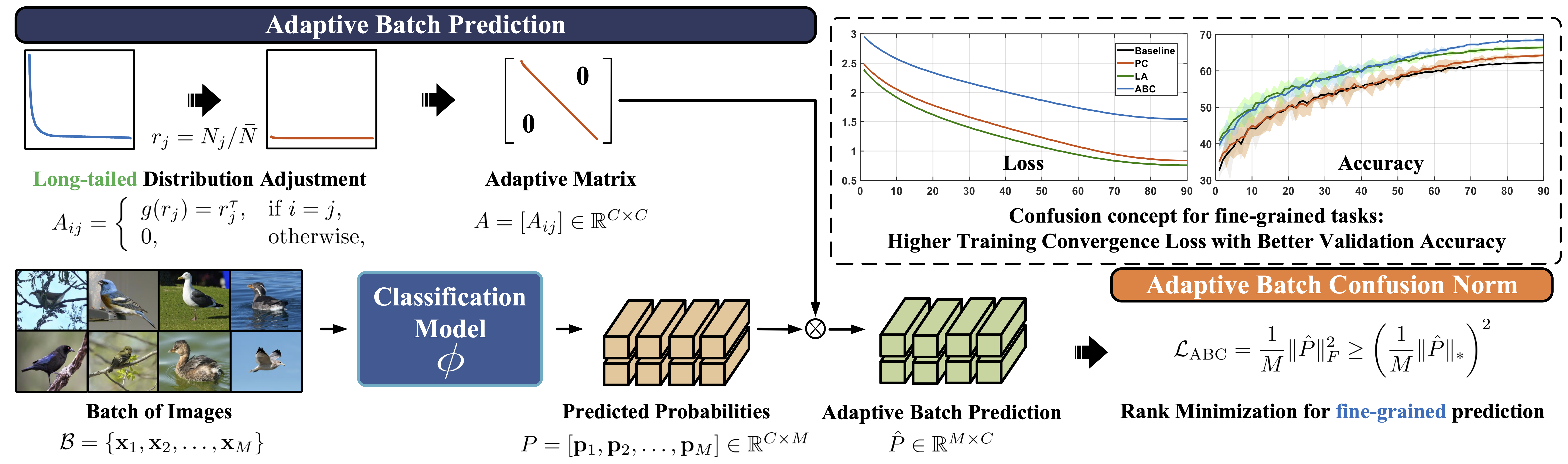
圖二:Adaptive batch confusion norm (ABC-Norm)方法概述 - 開發基於3D點雲的電腦視覺技術:我們的主要目標是開發具智慧製造應用潛能的3D電腦視覺技術。有鑑於描述3D室內場景的主流數據格式為點雲,且通常為大數量點集合。為了促進其相關技術在電腦視覺的實際應用,本研究尋求為處理點雲集建立採樣策略,以便由此產生的資料縮減具代表性,且能提升深度學習模型的處理效率。此外,我們的另一個研究重點是開發基於點雲的3D異常檢測技術,目前為止已獲有不錯的初步成果。
- 開發小樣本或語言驅使深度學習技術應用於動作行為偵測與分析:少例題示的動作行為偵測(Few-Shot Action Detection, FSAD)原理,可藉由所提供的少量支持集(support set),從未修剪的查詢視訊中偵測出模型訓練時從未見過的動作行為類別。現有的FSAD 技術主要依賴於從查詢視訊中生成一組與類別無關的動作候選集,透過評估它們與支持集的相關性來找到最合理的動作候選建議。這種兩階段方法雖然可行但效率不明確,主要是因為在生成動作候選集時忽略了支持集的有用提示。我們的演算法只需提供單張影像作為支持集,再利用所開發的注意力聚焦策略,在生成候選集的同時有效地逐步執行支持查詢交叉注意力。由此產生的單一階段模型會產生高質量的動作候選集,以提高單例(single-shot)動作行為偵測效能。
- 開發非監督式Representation Learning方法:對比學習(Contrastive Learning, CL) 是自監督學習最成功的範例之一。在其方法原理上,它認為來自同一影像的兩個增強視圖為positive所以需要被拉近,而與來自其他影像會是negative,應該被推得更遠。然而,在基於CL架構所取得令人矚目成功的背後,它們的學習訓練過程往往依賴於繁重的計算設置,包括大樣本批次、大量訓練時期等。針對此缺點,我們建立一個簡單、高效且具有競爭力的方法,可作為對比學習的基線。具體來說,我們從理論和實證研究中發現,廣泛使用的 InfoNCE 損失中存在明顯的負-正耦合(Negative-Positive Coupling, NPC)效應,導致批量大小的學習效率不佳。通過消除NPC效應,我們提出了解耦對比學習(Decoupled Contrastive Learning, DCL)損失,只要從分母中去除了正項,即可顯著提高訓練學習效率。DCL的優點是對次優超參數不敏感的情況下實現了有競爭力的效能,改進了諸如在 SimCLR中的大批量、MoCo中的動量編碼,或者large epochs的複雜運算需求。