PIs: Ding-Yong Hong and Jan-Jan Wu
This collaborative project aims to enhance the execution performance of deep learning applications. It was motivated by the increasing complexity of deep learning models, which are becoming deeper, wider, and more complex. These models are widely deployed in a variety of intelligent systems, such as self-driving cars and voice assistants. Though such models have significantly improved prediction accuracy, they also significantly increase the execution time. On the other hand, the wide adoption of heterogeneous system architectures (HSA) in modern computers, which integrate various computing devices such as CPUs, GPUs, FPGAs and AI accelerators, provides ample opportunities for improving the execution efficiency of those complex deep learning models. The collaborative project addresses this challenge from the aspect of compiler optimization and computer architectures, and designs efficient scheduling and parallelization methods. Our research results have been published in top journals and conferences. Our contributions also received a research award, as well as fostered the industry-academy collaboration with Delta Electronics, a company building intelligent systems, and National Taiwan University, starting in August 2022.
This project reduces the execution time of deep learning models in three directions: 1) designing efficient scheduling algorithms for executing any complex models on any heterogeneous systems; 2) maximizing the utilization of computing resources; and 3) generating high-performance execution code for compressed models, such as pruned and quantized neural networks.
Scheduling algorithm design
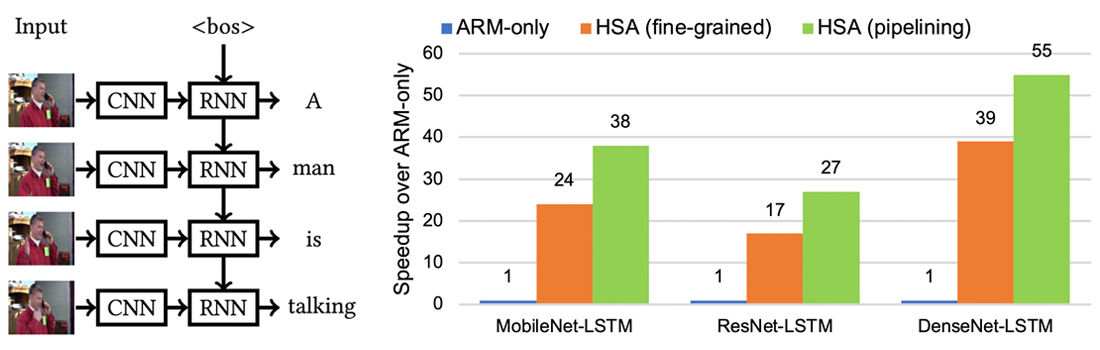
Designing a good scheduling on heterogeneous systems should address four issues. First, since the system is heterogeneous, we need to assign the network models to appropriate devices to reduce the computation cost. Second, we should choose the scheduling granularity carefully. The computation behaves very differently if we schedule one model at a time (coarse-grained), or we schedule one operation at a time (fine-grained). Third, we need to carefully schedule the tasks so that the execution dependency is not violated and no tasks use the same device at the same time. Finally, we should reduce the communication overhead when two related tasks are mapped to different devices. To this end, we proposed an efficient dynamic programming to solve the scheduling problem by using a pre-built cost model, which can accurately predict the computation and communication time of model operations on heterogeneous devices. We also developed a pipeline scheduling method to overlap the execution of independent operations on different devices so as to exploit maximal parallelism. Take the hybrid CNN+RNN video captioning application in Figure 1 as an example. With the collaboration of the ARM CPU and two EdgeTPUs (Figure 1b), our fine-grained scheduling, which maps model operations to their most suitable computing devices, improves DenseNet-LSTM by a factor of 39× over the ARM-only execution. The speedup is further improved to 55× by scheduling the independent operations in a pipeline manner, achieving a captioning performance of 59 frames per second. To the best of our knowledge, this is the first effort to achieve real-time video captioning on the edge device for the large DenseNet-LSTM model. This work is published in the top conference, IEEE IPDPS’21, and the top journal, ACM TACO, in 2022. Furthermore, we tackle the more complex deep learning models, such as NASNet, ResNext and ensembles, which have the computational graphs of branch structure or complex data dependency, leading to two challenging issues. First, the complex structure makes it hard to find a good execution order for the model operations. Second, modern hardware has high computational power; running operations sequentially could under-utilize the resources of modern hardware. We address these issues by exploiting inter-operator parallelism, i.e., parallelism among independent operations, to utilize the hardware resources more efficiently. However, naively running independent operations in parallel could overwhelm the accelerator and harm the performance. Therefore, we proposed a resource utilization-aware scheduling to exploit parallelism among model operations. Our scheduling improves model performance by 3.76× on the Nvidia RTX 3090 GPU, compared to the sequential execution in TVM, a state-of-the-art production-level AI compiler. This work won the best paper runner-up award at ICPADS’22.
Maximizing resource utilization.
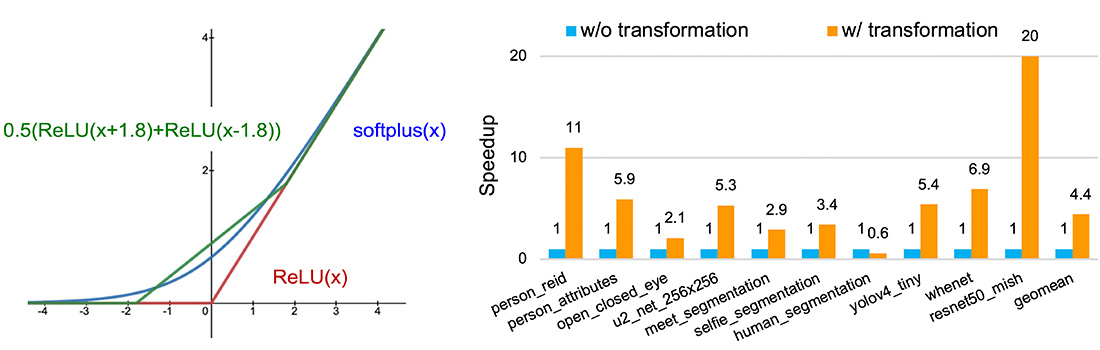
The increasing demand for energy-efficient and high-performance computing calls for domain-specific architectures, e.g., the Google EdgeTPU for accelerating deep learning inference. Most deep learning accelerators support a limited set of operations. When a model contains unsupported operations, such operations are executed on an auxiliary processor such as the CPU, which could result in significant overhead switching between the accelerator and CPU and the under-utilization of the accelerator. To overcome the problems, we designed a model rewriting tool to replace unsupported operations in the model with supported ones of equivalent functionality. Moreover, we proposed a novel and general method to approximate arbitrary continuous functions to any precision by using the widely-supported ReLU operation, thus, any accelerators supporting ReLU can benefit from our method. Figure 2a shows an example of approximating softplus with two ReLUs. Figure 2b shows that our method improves model performance by 4.4× on average over the models without our transformation on an ARM+EdgeTPU edge platform. This work is published in the ICPADS’22 conference.
High-performance code for compressed models.
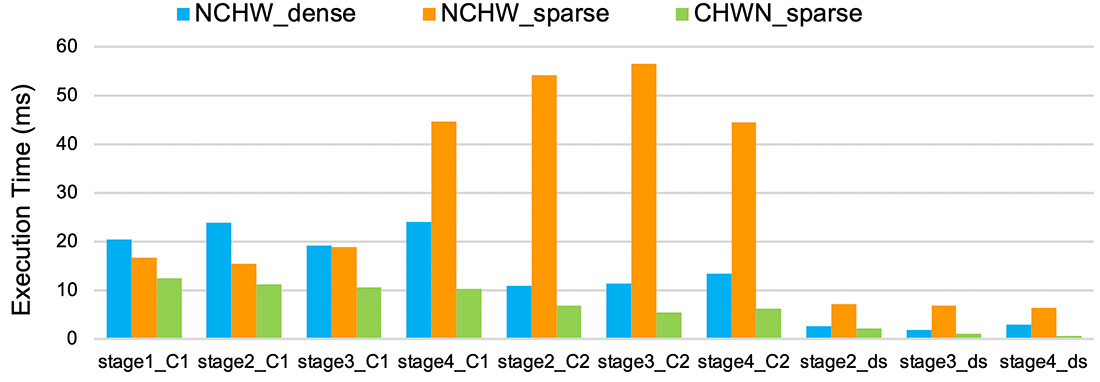
Model compression, such as pruning, quantization, and knowledge distillation, is a technique to reduce memory requirement and computational complexity of deep learning models. It is especially important for deploying models on devices with limited resources or low computational power. Typically, special hardware is required to run compressed models efficiently. However, in this work we demonstrate that a software-hardware co-optimization method can achieve competitive performance on general-purpose hardware such as CPUs. Based on the TVM compiler framework, we developed several optimizations to exploit cache locality, vectorization and masking that are commonly-supported by modern CPUs, and successfully generate high-performance execution code for the compressed models via state-of-the-art compression techniques, including column combining and fine-grained structured pruning. The ResNet18 example in Figure 3 shows that our optimizations significantly reduce the inference time of the sparse model for all convolution layers, compared to the dense counterpart.