PIs: Wei-Yun Ma and Hsin-Min Wang
The potential market for chatbots is quite large globally. Still, the critical challenge is that developing an intelligent chatbot requires significant time and effort for developers to write scripts or provide training data. Collecting a large amount of dialogue material for any specific product type is tricky.
Therefore, in 2023, Dr. Ma and Dr. Wang's research teams formed a collaboration project to address the challenge, funded by the Institute of Information Science at Academia Sinica (2023/1~2024/12). We proposed a bold idea called "Data to Chatbot," which aims to develop a platform that can automatically design dialogue scripts and even promotional strategies for products without the need for training data or scriptwriting. It can interact with users through text or voice; the entire process is "intelligent manufacturing."
The key lies in where the chat material for specific products comes from. We use information extraction and text summarization technology to search for and extract suitable chat materials and convert them into spoken expressions. In fact, besides information from catalogs, many products have a large number of user experience articles online. Thus, using these first-hand user experiences as chat material can be factual and persuasive, providing warm and differentiated recommendations. At the same time, we also use these user experience articles as training materials for spoken language understanding.
The overall architecture is shown in Figure 1, where the orange box represents Natural Language Processing (NLP) related techniques, and the green box represents Spoken Language Processing (SLP) associated techniques. The red font indicates the new technology developed in this project. The user's speech is automatically recognized by the Automatic Speech Recognition (ASR) module, which converts it into text and extracts keywords. The text is processed by the Natural Language Understanding (NLU) module for intent classification and keyword extraction. The keywords generated by both approaches are then integrated to form the Semantic Frame representation of the user's input speech, which is then passed to the Dialogue Management (DM) module to determine the response strategy and track the current dialog status. The Natural Language Generation (NLG) module generates the textual responses based on the Semantic Frame and response strategy, which is then converted into speech signal by the Text to Speech (TTS) module and returned to the user.
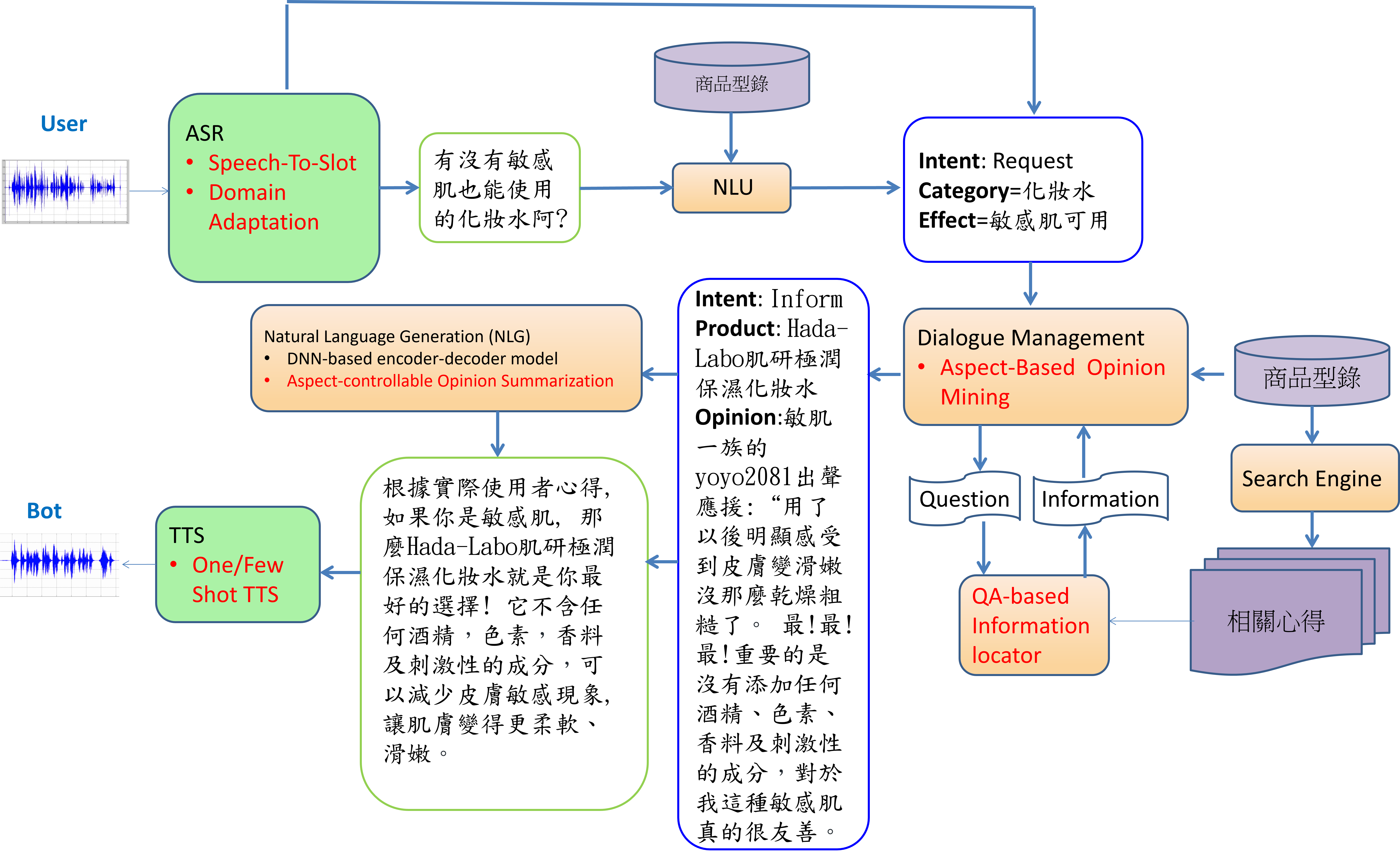
We employ information extraction and text summarization techniques to extract appropriate chat material from user experience articles online. The articles are usually enormous and diverse, and even if they are all about a specific product, most may not be suitable as chat material. Searching for appropriate and persuasive chat material and rewriting it from written to spoken language is challenging. Our technology can generate chat material for any specified aspect (such as specific product efficacy). In the past, we have achieved good results by using different "dishes" mentioned in restaurant reviews as the specified aspect. In this project, we are focusing on beauty and skincare as the main field and using various product efficacies (such as "moisturizing," "whitening," etc.) as the specified aspects to generate chat material. We are further developing a model to evaluate whether the generated text is attractive by scoring it. Then, we use this attractiveness score to optimize text generation further using reinforcement learning, making the generated text more appealing.
Regarding speech understanding, the traditional approach is the pipeline method, which involves using Automatic Speech Recognition (ASR) to transcribe the input speech into text, followed by Natural Language Understanding (NLU) to extract meaning. However, this segmented approach can result in error propagation issues. We will use the pipeline approach as the baseline model and investigate it with a new end-to-end Spoken Language Understanding (SLU) technology that directly extracts meaning from speech.
In terms of speech generation, in addition to providing a general multi-lingual Text-to-Speech (TTS) system that can output speech using a specific speaker's voice, we will develop new One/Few Shot TTS technologies to meet the requirement of adding new speakers’ voices at will. Training ASR and SLU models traditionally requires a large amount of annotated speech data within the domain. To avoid the manual efforts, we are also developing new multi-lingual TTS and one-shot/few-shot TTS technologies for data augmentation, i.e., automatically generating speech training data for ASR and SLU.